
The H3Africa Biospecimen and Data Catalogue offers researchers the ability to search information about H3Africa studies. As part of funder requirements, H3Africa samples are deposited in three H3Africa biorepositories and genomic data is submitted to public repositories such as the European Genome-phenome Archive (EGA) or the European Nucleotide Archive (ENA).
The objective is to facilitate further research that will benefit study participants. Access to data and biospecimens is controlled by the H3Africa Data and Biospecimen Access Committee (DBAC).
The Catalogue is updated periodically with metadata from studies uploaded from the H3Africa Archive hosted by H3ABioNet and the corresponding biospecimen metadata uploaded from the three H3Africa biorepositories; IBRH3AU, CLS and I-HAB.
The H3Africa archive is a custodian of the H3Africa genomic and phenotype data and prepares the data for submission to the EGA or ENA. Metadata from the archive and biorepositories are submitted to the catalogue monthly to enable users to search:-
- Study – by study name, design or disease
- Participant type – by sex, ethnicity or case/control
- Biospecimen – by country of origin, type or feature
From search results users can submit a request for access to the DBAC. To access the Catalogue, click here
The catalogue architecture
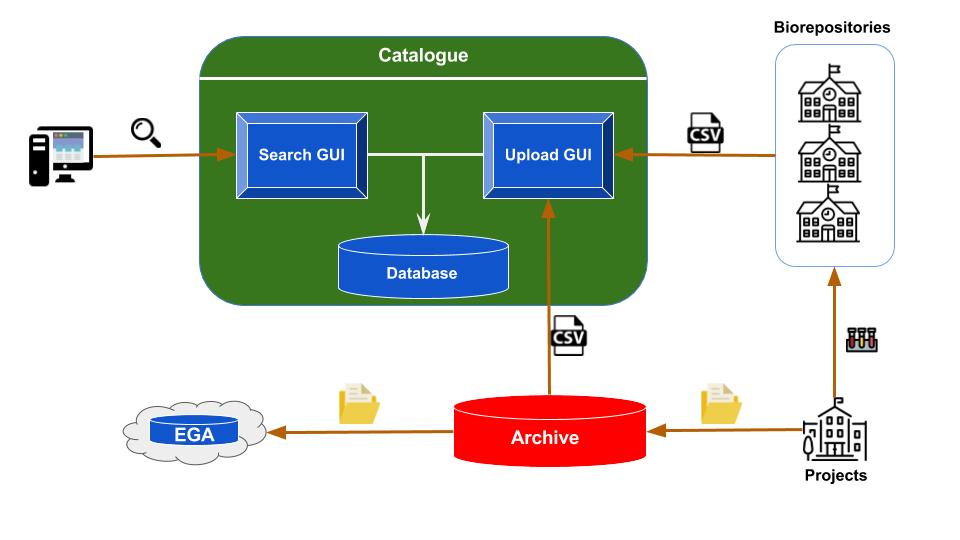
Overview of the catalogue architecture. At the bottom right are the institutions running the studies, collecting the biospecimens, processing them and generating genomic and phenotype data. A portion of the biospecimens, along with their metadata are sent to one of the biorepositories. The biorepositories update the content of their LIMS with the new information. The genomic datasets generated from the studies are sent to the Archive, where they are held for a period of 9 months before submission to public repositories. The Archive and biorepositories export csv files with metadata for each project and upload them into the catalogue, triggering an update of the catalogue database.



